Generated Documentation, part 2
Wednesday, November 26th, 2008As I noted previously, I’ve been using our static analysis tools to generate documentation for the Mozilla string classes.
All of the code to generate this documentation is now checked in to mozilla-central. To regenerate documentation or hack the scripts, you will first need to build with static-checking enabled. Then, simply run the following command:
make -C xpcom/analysis classapi
To automatically upload the documentation to the Mozilla Developer Center, run the following command:
MDC_USER="Your Username" MDC_PASSWORD="YourPassword" make -C xpcom/analysis upload_classapi
One of the really exciting things about the Dehydra static-analysis project is that the analysis is not baked into any compiler. You can version your analysis scripts as part of your source code, run them from within your build system, and change them as your analysis needs change.
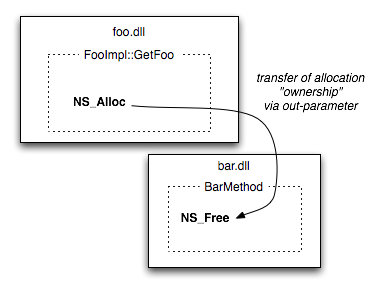
For example, I decided that a class inheritance diagram would help people understand the Mozilla string classes. So I modified the documentation script to produce graphviz output in addition to the standard XML markup. I then process the graphviz output to PNG with an imagemap and upload it to MDC along with the other output as an attachment1.
The output is available now. I’m still looking for volunteers to improve the output as well as the source comments to make it all clearer!
1. There is a MediaWiki extension so you can put graphviz markup directly in a wiki page and it will be transformed automatically. However, this extension currently doesn’t work on the Mozilla Developer Center. It’s being tracked in bug 463464 if you’re interested. ^