Using Mercurial Revsets to Search for Changes Between Firefox Releases
Monday, July 9th, 2012I was recently asked to provide a list of all the plugin-related changes from Firefox 11 to 12 to 13. This is actually not the easiest question to answer: both bugzilla and source code searches may produce false negatives and false positives.
Using bugzilla to answer this kind of query fails whenever the bugzilla metadata is incorrect or misleading. Usually the Target Milestone for a fixed bug indicates the release version that it first ships in, but it is not uncommon to forget to set the TM for bugs. And when a bug is backported to an earlier train, the target milestone doesn’t always get moved backwards to match. In addition, filtering by bugzilla component often leaves out important bugs, since changes to graphics, DOM, layout, or JS can make noticeable changes in plugin code.
Instead, I decided to use Mercurial to answer this question. Almost all changes which affect plugin function are going to be located in the following directories and files:
- dom/plugins
- content/base/src/nsObjectLoadingContent.{h,cpp}
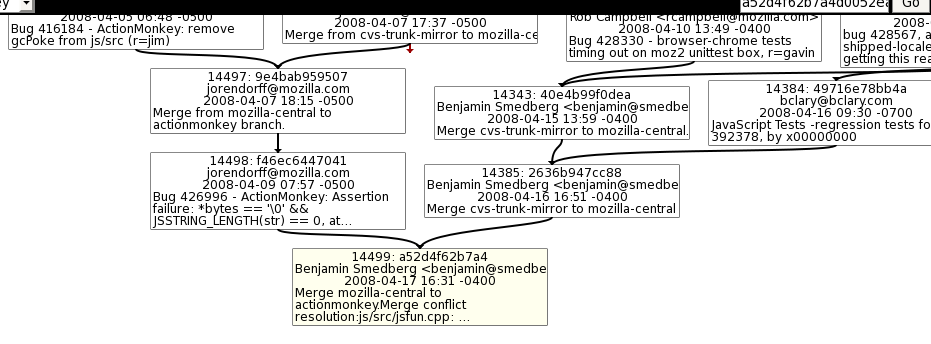
So what I really wanted was a list of changes between two Firefox releases which touch that set of files. But how can I use Mercurial to search only the revisions between two specific releases? Here is the branch diagram for the Firefox trains:

By default, hg log -rfoo:bar will list the changes between two particular revisions in whatever linear order these revisions happened to be pulled into your repository. This means that you may get different results depending on the order you pulled. But there is a feature in Mercurial called “revsets” that lets you pick changes in much more specific ways. For more information about revsets, issue hg help revsets or see the online documentation.
In this case, I wanted to log all the revisions between the mozilla-central branch point of Firefox 12 and the release of Firefox 13. Revsets can figure the branch point with the ancestor operator, and can then list all the changesets between two revisions (including all branch/merge revisions) with the :: operator. So the final command for finding all changes which touch plugin files between Firefox 12 and 13 was:
$ hg log -r "ancestor(FIREFOX_12_0_RELEASE,FIREFOX_13_0_RELEASE)::FIREFOX_13_0_RELEASE" dom/plugins/ content/base/src/nsObjectLoadingContent.{h,cpp}
Special thanks to Dirkjan Ochtman (djc) for introducing me to revsets!